

Cost Of Self Hosting Llama-3 8B-Instruct
自我托管的成本 Llama-3 8B-Instruct
Sid Premkumar
, Sid Premkumar、Thu Jun 13 2024 2024 年 6 月 13 日星期四•llama-3 骆驼-3

How much does it cost to self host a LLM?
⚡️ TLDR: Assuming 100% utilization of your model Llama-3 8B-Instruct model costs about 1 per 1M tokens. Choosing to self host the hardware can make the cost <$0.01 per 1M token that takes ~5.5 years to break even.
⚡️ TLDR:假设您的 Llama-3 8B-Instruct 模型 100% 使用 EKS 自托管,则每 100 万个代币的成本约为 17 美元,而 ChatGPT 在相同工作量下每 100 万个代币的成本仅为 1 美元。选择自行托管硬件可以使每 100 万个代币的成本低于 0.01 美元,这需要 ~5.5 年才能实现收支平衡。
A question we often get is how do you scale with ChatGPT. One thing we wanted to try is to determine the cost of self hosting an open model such as Llama-3.
我们经常遇到的一个问题是如何扩展 ChatGPT。我们想做的一件事就是确定自行托管 Llama-3 等开放模型的成本。
Determining the best hardware
Context: All tests were run on a EKS cluster. Each test was allocated the resources of the entire node, nothing else was running on that node other than system pods (prometheus, nvidia-daemon, etc.)
背景:所有测试均在 EKS 集群上运行。每个测试都分配了整个节点的资源,除了系统 pod(prometheus、nvidia-daemon 等)外,该节点上没有运行其他任何东西。
We first wanted to start small, can we run it on a single Nvidia Tesla T4 GPU? I started with AWS’s g4dn.2xlarge instance. Its specs were as follows (source (opens in a new tab)):
我们首先想从小规模开始,能否在单个 Nvidia Tesla T4 GPU 上运行?我从 AWS 的 g4dn.2xlarge 实例开始。其规格如下(来源):
- 1 NVidia Tesla T4
- 32GB Memory. 32GB 内存
- 8 vCPUs 8 vCPU
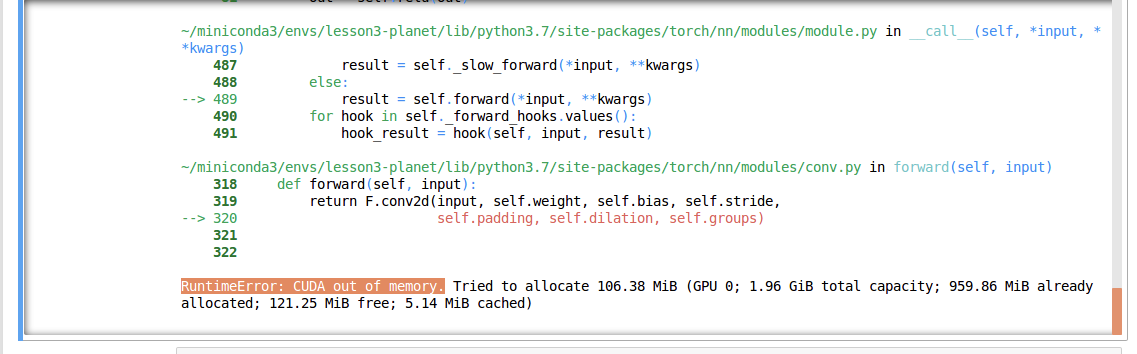
The short answer is that running either the 8B param or the 70B param version of Llama 3 did not work on this hardware. We initially tried the 70B param version of Llama 3 and constantly ran into OOM issues. We then sobered up and tried the 8B param version. Although this time we was able to get a response, generating the response took what felt like ~10 minutes. I checked nvidia-smi and the single GPU was being used, it just wasn’t enough.
简而言之,在这种硬件上运行 8B 参数或 70B 参数版本的 Llama 3 都无法正常工作。我们最初尝试了 70B 参数版本的 Llama 3,但经常出现 OOM 问题。后来我们冷静下来,尝试了 8B 参数版本。虽然这次我们能得到响应,但生成响应却花了大约 10 分钟。我检查了 nvidia-smi ,发现单 GPU 也在使用,只是不够用。
For context 8B vs 70B refers to the parameters in the model and generally translate to performance of the model. The advantage of the 8B param is its small size and resource footprint.
就上下文而言,8B 与 70B 指的是模型中的参数,一般转化为模型的性能。8B 参数的优点是体积小、占用资源少。
So I decided to switch to the g4dn.16xlarge instance type. The specs of that were as follows (source (opens in a new tab)):
因此,我决定改用 g4dn.16xlarge 实例类型。其规格如下(来源):
- 4 NVidia Tesla T4s
- 192gb memory 192GB 内存
- 48 vCPUs 48 个 vCPU
Initial Implementation 初步实施
My initial implementation involved trying to copy and paste the code present on the llama-3 hugging face (see (opens in a new tab))
我在最初的实施过程中,尝试复制和粘贴存在于 llama-3 抱抱脸上的代码(见)
These results seemed a lot more promising as the response time lowered from ~10m to sub 10 seconds consistently.
这些结果似乎更有希望,因为响应时间从大约 10 米持续缩短到 10 秒以下。

I was able to get a response in a much more reasonable 5-7 seconds. At this point I wanted to start calculating the cost of this request.
我只用了 5-7 秒就得到了合理得多的回复。此时,我想开始计算这个请求的成本。
g5dn.12xlarge costs $3.912 per hour on demand (see (opens in a new tab)).
g5dn.12xlarge 的需求成本为每小时 3.912 美元(见)。
If we assume a full month of use, that costs:
如果假定使用一个月,费用为
I had trouble with getting the token count in hugging face so ended up using llama-tokenizer-js (opens in a new tab) to get an approximation of tokens used.
我在获取 “拥抱脸 “中的令牌数时遇到了麻烦,因此最终使用 llama-tokenizer-js 来获取令牌使用量的近似值。
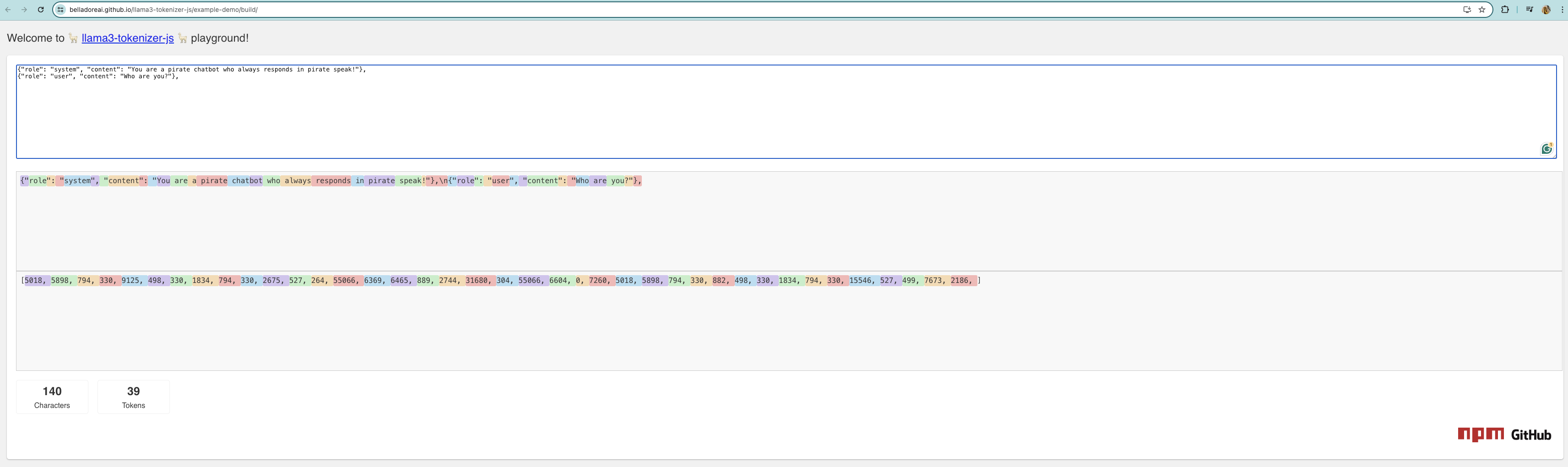
Note: This ended up being incorrect way of calculating the tokens used.
注:这是计算所用代币的不正确方法。
If we look at this result, we assume we used 39 tokens over ~6 seconds. Assuming Im processing tokens 24/7, extrapolating that we get:
如果我们看一下这个结果,假设我们在 ~6 秒内使用了 39 个令牌。假定 Im 24/7 处理令牌,推断出:
With 6.5 tokens per second, over the month I can process:
以每秒 6.5 个令牌计算,一个月下来我可以处理 6.5 个令牌:
With 16,848,000 tokens per month, every million tokens costs:
每月有 1684.8 万个代币,每一百万个代币的成本:
😵Yikes. It is not looking good. Lets compare this to what ChatGPT 3.5 can get us.
😵呀。看起来不妙。让我们把它与 ChatGPT 3.5 能带给我们的东西进行比较。
Looking at their pricing (opens in a new tab), ChatGPT 3.5 Turbo charges 1.5 per 1M output token. For sake of simplicity, assuming an average input ratio, that means per 1M tokens they charge 167.17.
从定价来看,ChatGPT 3.5 Turbo 每 100 万个输入代币收取 0.5 美元,每 100 万个输出代币收取 1.5 美元。为简单起见,假设平均输入输出比为 1:1,这意味着每 100 万个代币收费 1 美元,这就是要击败的数字。与我的 167.17 美元相差甚远。
Realization Something Was Wrong
At this point I felt I was doing something wrong. Llama 3 with 8B params is hard to run, but I didn’t feel it should be this hard, especially considering I have 4 GPUs available 🤔.
此时,我觉得自己做错了什么。带有 8B 参数的《Llama 3》很难运行,但我觉得不应该这么难,尤其是考虑到我有 4 个 GPU 可用🤔。
I decided to try to use vLLM to host an API server instead of attempting to do it myself via hugging face libraries.
我决定尝试使用 vLLM 来托管一个 API 服务器,而不是试图自己通过抱脸库来做这件事。
This was dead simple and just involved me installing ray and vllm via pip3 and then changing my docker entry point to:
这非常简单,我只需通过 pip3 安装 ray 和 vllm ,然后将 docker 入口点更改为
Specifically noting that I call —tensor-parallel-size 4 to enforce that we use all 4 GPUs.
特别要注意的是,我调用 —tensor-parallel-size 4 来强制使用全部 4 个 GPU。
Using this got significantly better results.
这样做的效果明显更好。
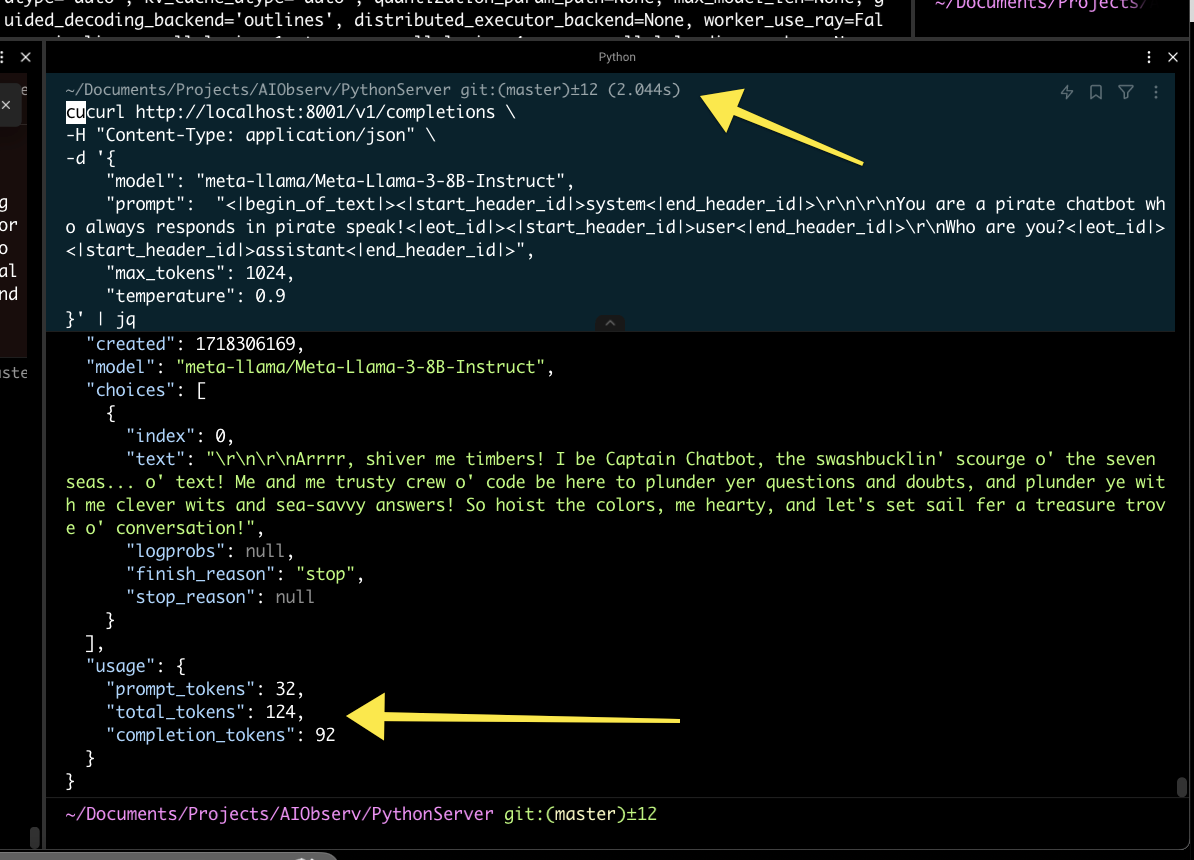
In this example you can see the query took 2044ms to complete. This was also the time I realized my previous method of calculating token usage was incorrect. vLLM returned the tokens used which was perfect.
在这个示例中,您可以看到查询耗时 2044 毫秒才完成。这也是我意识到之前计算令牌使用量的方法不正确的时候。
Going back to cost, now we can calculate tokens per second:
回到成本,现在我们可以计算每秒的代币:
Again assuming I produce tokens 24/7, this means that I can ingest a total of:
再次假设我全天候生产代币,这意味着我总共可以摄入:
Which means the cost per 1 million tokens would cost me:
也就是说,每 100 万个代币的成本就是我的成本:
Unfortunately this is still not below the value that ChatGPT offers, you’d lose about $17 a day 😭
不幸的是,这仍然不低于 ChatGPT 提供的价值,您每天将损失约 17 美元 😭
An Unconventional Approach
Instead of using AWS another approach involves self hosting the hardware as well. Even after factoring in energy, this does dramatically lower the price.
另一种方法是不使用 AWS,而是自行托管硬件。即使考虑到能源因素,这也能大幅降低价格。
Assuming we want to mirror our setup in AWS, we’d need 4xNVidia Tesla T4s. You can buy them for about $700 dollars on eBay
假设我们想在 AWS 中镜像我们的设置,我们需要 4xNVidia Tesla T4。你可以在 eBay 上以约 700 美元的价格买到它们
Add in $1,000 to setup the rest of the rig and you have a final price of around:
再加上安装其他设备的 1,000 美元,最终价格约为 1,000 美元:
If we calculate energy for this, we get about ~$50 bucks. I determined power consumption by 70W per GPU + 20W overhead:
如果按此计算能耗,大约需要 50 美元。我按照每个 GPU 70W + 20W 的开销来计算功耗:
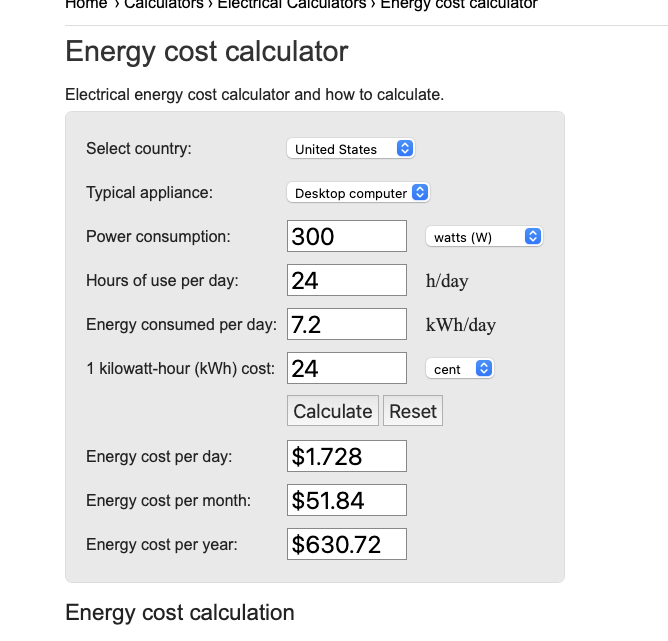
After factoring in the ~50 bucks, lets round up to ~$100 to factor any misc items we might have missed.
扣除约 3 800 美元的固定成本后,每月成本约为 50 美元,四舍五入后约为 100 美元,以考虑我们可能遗漏的任何杂项。
Re-calculating our cost per 1M tokens now:
现在重新计算每 100 万个代币的成本:
Which is significantly cheaper than our ChatGPT costs.
这比我们的 ChatGPT 费用便宜得多。
Trying to determine when you’d break even, assuming you want to produce 157,075,200 tokens with ChatGPT, you’re looking at a bill of:
假定您想通过 ChatGPT 生产 157,075,200 个代币,要确定何时才能实现收支平衡,您需要支付的账单是
You have a fixed cost of ~57. To make up your initial server cost of $3,800, you’d need about 66 months or 5.5 years to benefit from this approach.
您每月的固定成本约为 100 美元,因此 “利润 “为 57 美元。若要弥补初始服务器成本 3,800 美元,您需要大约 66 个月或 5.5 年的时间才能从这种方法中获益。
Although this approach does come with negatives such as having to manage and scale your own hardware, it does seem to be possible to undercut the prices that ChatGPT offer by a significant amount in theory. In pracitice however, you’d have to evaluate how often you are utilizing your LLM, these hypotheticals all assume 100% utilization which is not realistic and would have to be tailord per use case.
虽然这种方法有一些不利因素,比如需要管理和扩展自己的硬件,但从理论上讲,它确实有可能大大低于 ChatGPT 提供的价格。但在实际操作中,您必须评估 LLM 的使用频率,这些假设都是假定 100% 的使用率,但这并不现实,必须根据使用情况进行调整。
© lytix.ai.